Eugene Garfield and Irving H. Sher
Institute for Scientific Information,
3501 Market Street, Philadelphia, PA 19104
Brief Communication
JOURNAL OF THE AMERICAN SOCIETY FOR INFORMATION
SCIENCE, 44(5)
p.298-299, June 1993
Shortly after the publication of the primordial paper on Citation Indexing(Garfield, 1955), Robert Hayne and Eugene Garfield performed some experiments at SK&F Labs in 1957. They were interested in learning how much indexing information could be derived algorithmically from the titles of cited references in drug-related articles.
These unpublished experiments demonstrated that "derivative" indexing, i.e., using the titles of articles cited in a source text, would produce relevant indexing terms. In fact, the procedure anticipated most of the indexing terms assigned by experienced medical indexers. The major exceptions were terms for generic or tradenamed drugs. Normally, when the first article on a new drug is published, the drug name has never appeared in a title before. However, titles which include generic terms such as "anti-depressant" provide adequate indexing tags for such primordial articles.
To our knowledge, no further experiments of this kind were conducted until the time Harley (Gray & Harley, 1971) published the results of his pioneering experiments. In that now classical study of computer-assisted indexing, he used Medline® records to determine which MESH terms had been assigned to each of the cited references in a current source document. The results of that experiment were extremely positive. In fact, we had suggested, at one time, that this procedure be used to assign MESH terms to articles covered in the Science Citation Index®. Subsequently, K. L. Kwok reported an experiment on "The Use of Titles and Cited Titles as Document Representation for Automatic Classification" (Kwok, 1975), and stated that use of "cited title words offers a method intermediate between the use of citation identities alone and that of words from title and abstract, retaining some advantages of both."
Unfortunately, computer storage technology was then relatively primitive. We could not afford the large memory that would make it possible to access titles and/or indexing records for the references cited in each article. However, that has changed dramatically with the advent of affordable and fast gigabyte storage. With this capability in hand, ISI® was able to begin experiments with its internal Integrated Citation File, which contains complete source records for 20 years of data.
As part of an ongoing process of improving and upgrading ISI products, Irving Sher reinvestigated the feasibility of enhancing title word indexing by using title information in cited references. As a result of these experiments, combined with his experience in using similar procedures for algorithmically naming research fronts identified by cocitation clustering (Small & Garfield, 1986), he was able to develop the system named KeyWords PlusTM, which has been described recently (Garfield, 1990a, 1990b).
After each new source article is processed (each contains an average of 20 cited references), a computer program looks up the titles of all cited papers from the master source file that is, the articles ISI has processed within the last 20 years. The title words and phrases are tallied and various algorithms are used to select and rank the better three-word, two-word, and one-word candidate terms. The current system produces and saves up to 99 KeyWords PlusTM terms for each source item. Up to 10 of the top-ranking terms are now included in Current Contents on Diskette® (Garfield, 1988)
Tests of the innovation were made using a large number and variety of realistic search statements. So, we can talk preliminarily about "typical" results, effectiveness, and comparisons produced by different kinds of retrieval terms.
As a baseline, consider searches in which source title words alone retrieve
100 relevant items (see Fig. 1). Comparably, searches of KeyWords PlusTMproduce
another set of about the same size (102 articles). Of these, about 44 articles
overlap, but 58 additional relevant items are retrieved.
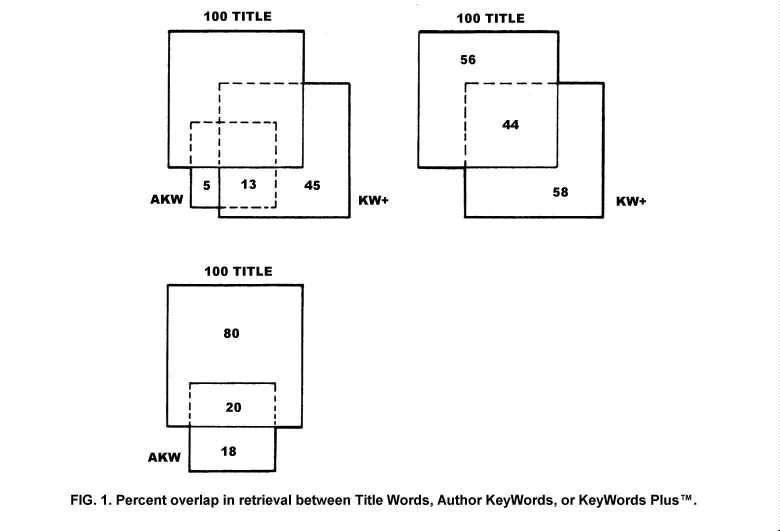
|
Comparable searches using author-supplied keywords produce a total set of 38 items, of which 20 overlap with the title set--but 18 supplement the title-word set. Of the 18 items, only 5 are not already identified among the 58 supplementary items from KeyWords PlusTM. The total augmentation of title retrieval by the combination of KeyWords PlusTM and author keywords is 63 additional unique items. Thirteen of the 63 items are in common between KeyWords PlusTM and author keywords, while 45 supplementary items are uniquely found only by KeyWords PlusTM.
Nevertheless, to take advantage of the relatively small but unique contribution by author keywords, author-supplied keywords are added to the database. This may also provide comfort to authors who created these keywords.
Citation Indexes were criticized from the outset because they lacked traditional "subject" or keyword access. For that reason, among others, we created the Permuterm Subject Index® (Garfield, 1976). Presumably, librarians and others needed natural language entries for unfamiliar subjects for which they could not easily identify a starting reference or author in order to enter the Citation Index. The Permuterm Citation Index® section of the Science Citation Index® has proved extremely useful over the years. Now KeyWords PlusTM, as described above, significantly augments permuterm searching.
KeyWords PlusTM and searchable abstracts have already been incorporated into Current Contents on Diskette® Focus on Global ChangeTM, and Science Citation Index®. As time and programming permit, this enhancement is being built into all those ISI products for which it is relevant, e.g., discipline citation indexes, including neuroscience, biotechnology, materials science, and chemistry.
References
- back to textGarfield, E. (1955). Citation indexes for science: A new dimension in documentation through association of ideas.Science, 122, 108-111.
- back to textGarfield, E. (1976). The Permuterm Subject Index®: An autobiographical review,Journal of the American Society for Information Science, 27: 288-291.
- back to textGarfield, E. (1988, September 26). Introducing Current Contents on Diskette®: Electronic browsing comes of age,Current Contents®, 39, 3-8.
- back to textGarfield, E. (1990a, August 6). KeyWords Plus®: ISI's breakthrough retrieval method. Part 1. Expanding your searching power on Current Contents on Diskette,.Current Contents®, 32, 5-9.
- back to textGarfield, E. (1990b, August 13). KeyWords PlusTMtakes YOU beyond title words. Part 2. Expanded journal coverage for Current Contents on Diskette®, includes social and behavioral sciences,Current Contents®, 33, 5-9
- back to textGray, W.A., & Harley, A.J. (1971). Computer assisted indexing.Information Storage & Retrieval, 7, 367-174.
- back to textKwok, K.L. (1975). The use of titles and cited titles as document representation for automatic classification.Information Processing & Management, 11, 201-206.
back to textSmall, H., & Garfield, E. (1986). The geography of science: Disciplinary and national mappings. Journal of Information Science, 11, 147- 159.