Eugene Garfield
Institute for Scientific Information, Philadelphia, PA,
USA
Editorial introduction
Dr Garfield wrote this paper over 30 years ago, but for some reason it was not offered for publication. At that time he was affiliated to the Department of Structural Linguistics at the University of Pennsylvania, and from there he obtained his doctoral degree.When Dr Garfield offered us this paper we were, naturally, sufficiently intrigued to send it to two referees: an information scientist working on automatic indexing, and with leanings towards linguistics; the other a linguist with leanings towards information science (and both must forgive me for such glib descriptions).
The first referee recommended publication, if only on the grounds that "it is sobering to be reminded that work on automatic indexing has been going on for so long". The second referee had strong reservations, pointing out that the work of Harris and his colleagues is now well known in both the MT and IR fields; and that all of the ideas put forward by Garfield have been researched, elaborated and published by Naomi Sager, over ten years ago.
Accepting these reservations, we still considered that this paper was worth publishing, if only as a "sobering reminder". Thirty years after two seminal conferences at Dorking (1957) and Washington (1958), the majority of IR software vendors use the phrase "automatic indexing" to mean the creation of an inverted file.
In a paper presented at the First Symposium on Machine Methods for Scientific Documentation (Johns Hopkins University, March 1953) [1], I briefly described the very significant differences between "Machine Indexing, Machine Indexes and the Preparation of Printed Indexes by Machine Methods." It is always surprising that the distinction between these three very different activities is still not carefully drawn, in spite of protestations to the contrary. At an International Conference on Classification held in Dorking, May 1957 [2], I made the statement that most people refer to the use of machines for indexing purposes with the tacit assumption that the intellectual process of analyzing documents is done by conventional means, i.e. by human intellectual analysis. There is still little evidence to indicate otherwise. I raised this point again in Boston at a meeting of the Special Libraries Association (June 1957).
In Perrys work [3],[4], it has been basically assumed that telegraphic style abstracts will be used for indexing. However, these abstracts would be prepared by indexers. While Taubes indexing approach claims to be different from conventional indexing in large indexing centers, he makes no claim that his analysis can be mechanized. Uniterm indexing is presumably an improved human intellectual effort which differs from other human intellectual efforts. Perry [3] still talks about using the index to Chemical Abstracts (CA) as a basis for a machine index assuming that improved searching will result from "semantic factoring" of the indexing rubrics already chosen by CA indexers. These indexing descriptors, of course, are based on abstracts prepared by volunteer abstractors. More recently Luhn [5],[6] has made a definite attempt to analyze texts mechanically by "Auto-Encoding" and "Key Word in Context Indexing." He employs a statistical vocabulary analysis which we found, at Johns Hopkins, might have great promise as a first pragmatic approach to Mechanized Indexing, but which leaves much to be desired. In a personal communication to Professor Arthur Rose, Penn State University (1953), in connection with the work of the ACS Committee on the Mechanization of CA, I indicated that it is possible to locate over 60% of the indexing terms used in the Current List of Medical Literaturejustby analyzing the titles of the articles. This was reported to the March, 1953 Symposium during a question period in which Taube asked whether there was any basis for assuming that straight vocabulary analysis would produce most of the indexing terms needed. The study also indicated that another 30% of the indexing terms that had been used were implied by the vocabulary in the titles of articles. For example, adrenaline implied epinephrine and cortisone implied steroids. The remaining 10% could usually, but not always, be found by analyzing the vocabulary of the text of the article itself.
These percentages varied for chemical abstracts as titles of chemical articles were frequently more "generic" in character and could not reveal as much information as the abstracts would. For example, an article on "5-alpha steroids" would have listed in its abstract the specific steroids synthesized.
In my reports on Citation Indexes, and particularly as reported to the Dorking Conference [2], I have stressed that one of its most promising features is that it begins to break the present barriers in attempting analysis of texts (indexing), but there are certain disadvantages unless the Citation Index is a facet of a total documentation system. A Citation Index by itself might fall short of the usual objectives of journal indexing. The Citation Index does go beyond the inherent limitations of a priori indexing, but it carries with it the shortcomings of present citation practices. Until we can get authors to standardize and systematize the citation of antecedent documents, the Citation Index will contain "noise" and also lack many pertinent citations. This, by no means, indicates that Citation Indexes are useless. Like other indexes, Citation Indexes are not perfect "solutions" to an, as yet, imperfectly defined problem.
For these reasons, I felt that actual mechanical indexing or analysis of texts must begin with some linguistic technique. In recent years, Newman, of the Patent Office has operated under a similar assumption for somewhat different objectives [7],[8].
In 1955, I was particularly intrigued by the potential application of Harriss Methods of Structural Linguistics [9] and said this in a proposal prepared for the National Science Foundation. In it I proposed that we study the possibility of indexing scientific documents by machine, using the methods of Structural Linguistics.
At about the same time, Harris, in part through contacts with Casomir Borkowski and me, became interested in the field of "Information Retrieval" and happily has conducted research in this field ever since. I am also glad to say that during this time my contacts with his work have been increasing. However, in this discussion of the semantic difficulties one encounters with the term "information retrieval"it is important to note that Harris is not entirely precise, I believe, in his use of the term "information retrieval". I am sure it is very different from the use of this term in documentation and library science. I presume he couldnt care less, since the objectives of his own research are primarily the better understanding of "language-structure theory, and ... a logistic system for science." (See paper No. 14 in Transformation and Discourse Analysis Projects, p. 1, University of Pennsylvania Department of Linguistics [10].)
When the linguist uses the phrase "Information Retrieval" or "for information retrieval purposes" he has in mind an entirely different set of ideas than the librarian, documentalist, or working scientist. It is my impression that "information retrieval", in relation to linguistic analysis, connotes the activities involved in locating particular words, phrases, or sentences of a particular text. Accomplishing this is no small task. It has an ultimate relationship to the problem of indexing scientific journals. However, it is intellectually more analogous to the tasks of book indexing and/or making concordances. Indeed, the work of R. Busa [11] on the use of IBM machines for preparing concordances has always had the linguistic flavor. This implied conception of "information retrieval" by Harriss group does not mean that the objectives of "Discourse Analysis" are limited to book indexing. Through Discourse Analysis one hopes to produce a boiled down version of a particular text, a process akin to "digesting" or "abstracting". If the Structural Linguists view the purposes of "information retrieval" otherwise, it has certainly not been evident in their writing or their out-loud speaking. One purpose of this paper is to point this out not in a deprecating sense, but merely as information which will help other workers in the field of information retrieval. It is a truism, but necessary to remind people, that the objectives of textual analysis vary considerably. My own specific interest is in finding a means of analyzing documents (mechanically or otherwise) so as to produce conventional index entries, which otherwise requires skilled human intellectual effort. This is no mean objective, with little hope for immediate results. However, studies in that direction may produce useful information. In fact, as Larkey stated in his paper on the Welch Medical Indexing Project [12], the study of machine methods forces us to re-evaluate our conventional methodsand analyze them in great detail. Any computer programmer knows this, but it was not so apparent several years ago.
In attempting to find a machine method of producing index entries by linguistic analysis, one not only has to re-evaluate known linguistic techniques for textual analysisone also has to look more closely at the indexing process. Since the purpose of my own studies in linguistics is to first become familiar with known techniques it would be presumptious of me to attempt any re-evaluation of linguistics at this stage of the game. On the other hand, my experience with indexing of several varieties does allow me to discuss intelligently what really does occur in the intellectual analysis necessary for conventional indexing.
Before doing this, however, I should like to summarize some of the salient features of Harriss Structural Linguistics. I would not like to leave the term "Discourse Analysis" dangling for those who are not familiar with it.
Scientific texts (discourses) consist of sequences of letters, combined into morphemes (or words), phrases, sentences.
The layman ordinarily thinks of sentences, if written (and if he thinks about them) as a sequence of words included between two punctuation marks called periods. Indeed, these are sentences but more than likely they are derived from, or may be factored into, two or more sentences. For example, in the sentence "I eat and I drink" one can easily recognise the two sentences "I eat" and "I drink". On the other hand, in the sentence "I eat and drink" it is a little less obvious that we have the same two small sentences "I eat" and "I drink". As sentences become more complex and involved these primordial relationships become even less obvious. Suffice it to say that it was no obvious discovery that "sentences" have the ability to appear in different states that are called "transforms" and that each language consists of a very small number of basic sentence types called "kernels". Out of this small array of sentence types, such as "noun-verb" (NV), any sentence of the language can be constructed. In Discourse Analysis, sentences are broken down into "sub-sentences" which may or may not be "kernels", i.e. irreducible basic sentence types. The sub-sentences are then arranged in such a fashion as to show maximal similarity between one another. By definition, different parts of these sub-sentences which share the identical "environment" are the same. Thus, from a sentence "Uruguay exports coffee and diamonds" we obtain, by the process of transformational analysis, two sub-sentences: Uruguay exports coffee" (A) and "Uruguay exports diamonds" (B). Then, since coffee and diamonds appear in the same environment, i.e., "Uruguay exports" we have established grammatical categories known as "equivalence classes". In this instance the equivalence class consists of coffee and diamonds. The operation involved in establishing these new grammatical categories is called the Equivalence Operation or Discourse Operation. As a result of the analysis we then say that coffee is "equivalent-sub 1 to diamonds". (coffee º1 diamonds). From this it is further derived that sentences A and B are equivalent-sub 2 (Aº 2 B), a secondary equivalence much the same as first cousin and second cousin. By continuing this process for a particular text a set of equivalence classes is yielded. The reduction of a text to its own set of equivalence classes constitutes Discourse Analysis.
"Transformational Analysis" is only a part of the armamentarium of Discourse Analysis. "Kernelization" is that use of Transformational Analysis for breaking down a text into its underlying basic components. I say "breaking down" with reservation as it is frequently a process of expanding into kernels.
For those whose are not familiar with conventional descriptive linguistics or structural linguistics, an examination of "The Transformational Model of Language Structure" by Z.S. Harris [13] will be well worth the reading. In this brief article Harris has kept to a minimum the technical jargon of both linguistics and mathematical logic.
This should then be followed by his paper in Area 5 of the International Conference on Scientific Information, Washington, November 1958 [14]. Subsequent reading of "Co-occurrence and Transformation in Linguistic Structure" will then be more productive [15].
A particular problem of mechanizing Discourse Analysis is similar to that encountered in mechanical translation of foreign languages. This is the problem of "Immediate Constituents" analysis. Here one has the problem of teaching the machine to recognize the proper phrasing brackets into which each word falls so that one can, subsequently, perform the actual Discourse Analysis. This is no small task. For example, the machine must be able to decide whether the word "paid" in "They have paid witnesses" is a part of a noun phrase or of a verb phrase. This is one of many problems of homonymity in language. Such syntactic or contextual analyses are truly a common problem area for Discourse Analysis, MT, and mechanical indexing.
The machine must first recognize what it is reading, unambiguously, before any decisions can be made concerning either translation, transformation, or indexing. It is somewhat confusing but actually Discourse Analysis can be an end in itself and it can also be used to further other objectives such as translation or indexing. I am somewhat surprised to find that the literature makes no apparent reference to this point. Later in this paper, I have tried to show, in a ye ry preliminary fashion, how the transformation operation of Discourse Analysis may be useful in furthering the specific objective of mechanical indexing. Before discussing the specific objectives of various information retrieval systems, let me point out some of the possible immediate values of Discourse Analysis for conventional library classification.
The above mentioned example of "Uruguay exports coffee and diamonds" is by no means an impractical one. It illustrates immediately the classificatory power of Discourse Analysis. The equivalence class, of which coffee and diamonds are members, is quite useful since it constitutes the class of "all those things which are exported from Uruguay." In a library one would expect to find a book on the "Exportation of Coffee from Uruguay" catalogued under: UruguayExports and/or ExportsUruguay. What then is so special about Discourse Analysis? The point is that subject headings are created at present by an intellectual determination on the part of the cataloger. We accept these "forms" as though they always existed but that is by no means the case. Further, to determine that a particular class does indeed exist, from mechanical analysis of the text, is quite different from intuitively deciding it exists. To create new classes, as it were, out of nowhere, is no small accomplishment if they are meaningful. To the Structural Linguist the existence of the heading URUGUAYEXPORTS is prima facie evidence for the existence of a new transformation. Uruguay Exports > URUGUAY EXPORTS. N1V2 > N1Nv2. A mechanical analysis of the book title would have produced this member of the class Nx Nvy even though "exports" did not previously exist in our standard list of subject headings or sub-headings. Indeed, I suspect that some studies along these lines would reveal some very useful new headings and subheadings for library catalogs. This would obviously not require machines.
Since the objectives of information retrieval systems vary considerably depending upon the requirements of the user, it is doubtful that any one methodology (such as Discourse Analysis) will serve all of these objectives. It is more productive if one states more precisely his specific objectives. Reducing lengthy texts to brief summaries (abstracts) is one distinct objective. In abstracting one strives to indicate either the principal subject matter (indicative abstracts) and/or the salient facts, conclusions or ideas reported (informative abstracts) [16]. However, these abstracts are written in "normal" English sentence style. If not, then we have a different objective.
If we desire to construct entries for an index to scientific papers, the salient subject matter of each paper will not be expressed in conventional sentences such as "This is an article about tobacco research" or "Rheumatics were studied after exposure to radiation". Rather, inverted phrases will be constructed to conform to the overall structure of the index. Our objective now becomes the selection of the main subject matter classes (rubrics). In addition, we may wish to construct useful modifying terms according to the particular system employed. Chemical Abstracts, Current List, Biological Abstracts, Engineering Index, etc. each have different structures. For example, some systems specifically use "sub-headings". The article on "Rheumatics exposed to X-radiation" can be indexed by the two descriptors RHEUMATISM and X-RAYS. However, under RHEUMATISM, material may be further sub-divided by a sub-heading "case histories". In addition to selecting the subject headings (rubrics) and sub-headings we may also wish to construct further modifying phrases (modifications) [cf. 16], which elaborate more specific information about the article. For example, "RHEUMATISM, case histories, after exposure to x-rays". And this can be carried even further [cf. 17], by adding a final phrase, which may be the only new information revealed, e.g., "RHEUMATISM, case histories, after exposure to x-rays, blood pressure increased by dose of 20 roentgens". There may have been dozens of other articles on "RHEUMATISM, case histories, after exposure to x-rays," but only one in which blood pressure effects were reported.
In taking any "linguistic" approach to indexing documents it is rather natural, as a first step, to think in terms of crude vocabulary analysis, with or without statistical considerations. After all, the individual words, particularly in a scientific text, should reflect what the text is all about. (The whole is the sum of its parts!) However, it is unfortunately true that vocabulary analysis is more useful in "book indexing" than in the indexing of large quantities of scientific articles. It is well known that the title of a scientific paper is indicative of the subject matter discussed. As mentioned earlier, it was found [1] that the words in titles are used, in one way or another, for indexing medical articles92% of the time. The percentage was lower for indexing chemical articles by Chemical Abstracts, but this variation depends, in part, upon the philosophy of indexing. Indexes based on indexing from the original article, i.e. subject bibliographies like the Current List, tend to be less specific than indexes to abstracts. In addition, the medical indexer will be content to index an article on "The Effect of Tranquilizers on Schizophrenics" under generic headings like TRANQUILIZERS or CNS DEPRESSANTS whereas the chemist expects more specific indexing for each chemical entity involved. In either case, it always pays to examine the title of an article as a preliminary clue to the further analysis of the text. This is even true in Discourse Analysis. Even more important, it will be quite revealing, I believe, to determine what linguistic or mental processes are involved that lead the author to choose a particular title.
Taube [18] has attempted to reduce indexing to the simple task of reading the vocabulary of the text without regard to synonymy. He assumes that users of indexes will make whatever associations are necessary to keep like things together. The fact that one man says adrenaline and another epinephrine, he does not consider important. This small point of synonymy, however, merely introduces us to the first stage of complexity involved in indexing since it is a far more complex relationship that the indexer establishes. For example, there are literally dozens of a priori classes of information concerning adrenaline from which an indexer can chooseand there may be absolutely no correlation between this. choice and the vocabulary of the document. Does the document concern the chemistry of adrenaline, synthesis, absorption, excretion, its effects on other modalities or drugs or vice versa, its analysis, its therapeutic effects or its side effects? Ultimately, it makes no great difference how you arrange the information in your indexwhat is important is that the relationships reported in the document are revealed by the indexing terms chosen or created.
We must find out not only how the indexer uses the vocabulary of the paper to indentify key words, but also how he uses the languages of the text to establish pertinent relationshipswhether they exist in the text or not, if indeed he does use the text that way. We must also study how he eliminates non-pertinent text which contains many otherwise potentially useful indexing terms. The "type" of indexing involved will affect the choice of terms created. I have mentioned before what I consider to be "a priori vs. a posteriori" indexing [19]. Either may draw on ideas not contained within a particular text. Sometimes it involves what is called in Discourse Analysis "metatext". (DA will have served a very useful function if these "metatexts" are carefully differentiated from the working text.) At other times indexing will involve ideation by the indexer in which a new relationship is established between the data reported and other known data. Each indexer has his own frame of reference. It will not be possible to report in this paper the linguistic process which may be involved. An "intuitive" Discourse Analysis may take place. Presumably the indexer works with a basic set of transforms which he finds useful for establishing ordered arrangements of ideas. Thus, in indexing an article "The Effects of Thorazine on Apo-morphine Induced Emesis in the Dog" an indexer, by a transformation operation obtains this transform: THORAZINE, effects on emesis, apo-morphine induced.
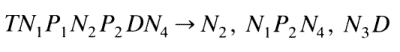
Taking the general case of this class of documents "The Effects of X on Y" we have:
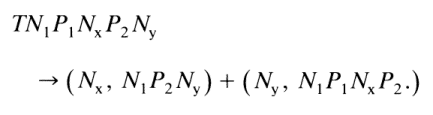
If one examines an index such as in Chemical Abstracts or the Current List, one finds that the number of transforms used appears to be large, but one questions their necessity. The actual existence of a small number of basic transforms in an index would be direct confirmation of Harriss, as yet, intuitive judgement that a language can indeed by reduced to a small number of transforms since the scientific index is an example of a language, even though somewhat artificial. One can roughly state that any index entry is of the form (N1, N2, N3,..., Nn) but this must be verified.
The next step in linguistic research on these indexes will answer the question: Does there occur a sentence in the original text from which each of the index entries was drawn that are indeed transformations of the index transforms. Or did the indexer first "summarize" the content of the document, with or without the help of the title, into a concise statement which contains an "incipient" transformation. And if so, how did he arrive at this since he has achieved, through some mental process, one objective of Discourse Analysisboiling down text and ideas. The final question is whether or not this "mental" analysis can be duplicated through Discourse analysis. Unfortunately the latter question may require a great deal of further research since Discourse Analysis itself, without a machine, is such a time consuming process. In the case of an analysis done by Harris, I have located an abstract prepared of this same article as well as some of the index entries used. This article is: The Structure of Insulin as Compared to That of Sangers A-Chain by K. Linderstrom-Land and John A. Schellman [20].
In Publication 3b, "Canonical Form of a Text", and in Publication 3c, "Sample Analysis of a Text", Transformations and discourse analysis prolects, University of Pennsylvania, Department of Linguistics [10], the above mentioned article is subjected to a Discourse Analysis. The result of this analysis is a series of tables which presumably summarize the information contained in the paper. Obviously this is no summary in the ordinary sense. It is also questionable whether a scientist would find these tables either meaningful or useful without considerable instruction. However, if the production of such tables could be mechanized they would be extremely valuable guides to the indexer or abstractor. This alone would be well worth the investment of time and energy. As greater sophistication is introduced into the techniques of transformation, the discourse operation, etc. these tables may become even more useful. Indeed, it may be that one will not need a set of "summarizing" tables but merely a set of transformations which have been standardized and in which redundancy has been eliminated. It is important to note that the summarizing tables do not, and cannot yet, make a distinction between levels of informational value. Of the information reported in Table 5 of the papers, only a small portion has been used in actual indexing of this article. This is not too disturbing since most of the terms which have been omitted, in conventional, i.e. CA, indexing, are terms which probably would not occur in a master dictionary of index headings. The further important difference between Discourse Analysis and indexing is that no distinction can be made easily between the really "new" information and that which is presented as historical background, etc. Further work on so-called metatext may make this easier.
A final point to be made about Discourse Analysis, Vocabulary Analysis
or any other mechanistic approach to indexing is that it will not be sufficient
to find ways of indicating everything reported in scientific papers, but
also ways of eliminating what is relatively unimportant. Otherwise every
search performed will choke the scientist with a flood of information that
will, thereby, be useless to him. Indexing involves not only the selection
of what is important but also the elimination of that which is unimportant.
Additional notes and appendix
(as yet incomplete but presented for possible interest)
(1) Many indexing operations can be resolved at the dictionary level. A straight vocabulary analysis of a text, followed by a matching operation in a dictionary, would produce many useful index entries. Unfortunately the amount of noise that would be introduced would make the index almost useless.
(2) A great deal of transformational work is obviously needed. The problem is where to start. One could begin with a study of the original texts and attempt to create index entries. However, it will probably be more useful and revealing to start with indexed texts, operate on these known transforms and work back towards the original text.
(3) In trying to locate the principal subject matter of texts, we must try to find out whether there are grammatical or syntactical "indicators" which point to the sentences or paragraphs which do contain this higher level information. For example, in the paper by Linderstrom-Lang on "The Structure of Insulin" the first paragraph is only introductory and reveals little or nothing of interest to the indexer. The subject matter "Optical rotatory power of proteins" does happen to be important in this article, but this is only definitely established in the second paragraph when the author states "one phase of this research, the dependence of ... is recorded here" (my emphasis). The phrase "one phase" refers to "... a study of the rotatory properties of several proteins including the effect of temperature, wavelength, pH, and the denaturation reaction."
In paragraph three the author states: "... all of the polypeptide systems which were investigated obeyed a one term Drude equation... "; In paragraph 7 he says "Instead it was found that"; "most striking is the fact that the ... "; "these results suggest that...". These italicized phrases have something in commonthey are all classified as METADISCOURSE. It will be an extremely interesting discovery if the occurrence of metadiscourse is the key to whether or not a sentence is considered of greater value for indexing purposes. This would be even more plausible if we keep in mind the possibility of first analyzing metadiscourse statements so as to characterize them for indexing purposes. The phrase "this research" is obviously a good clue to what must be indexed. So is the phrase "is recorded here." On the other hand, other metadiscourse statements such as "has often proved very useful" may not be useful to the indexer.
(4) Normal indexing of this document might have included the following:
(a) Insulin, structure of, compared to Sangers A-chain (used by CA)Actually practical limitations make such indexing impossible.
(b) Sangers A-chain, structure of Insulin compared to (not used)
(c) Proteins, optical rotatory properties of (used by CA)
(d) Wavelength, dependence of rotatory properties of proteins on (not used)
(e) Polypeptide systems obey one term Drude equation (not used)
(f) Drude equation (one term), obeyed in Polypeptide System (not used)
(g) Urea, denaturation of protein by (not used)
(h) Guanidine, denaturation of protein by (not used)
(i) Denaturation of proteins by urea and guanidine (not used)
(j) Clupein, specific rotations unaffected by strong solutions of urea and guanidine (not used)
(5) Sentences of a text may prove to be very informative for indexing papers. Certainly the text provides grist for the transformational mill. However, the amount of useful indexable information is still uncertain. What may be more important is that we will be able to characterize sentences more precisely. For example, one of the functions of good indexing is to relate two or more documents to each other if the relationship is a valid one. In paragraph 1 of the above paper, a sentence like "Single measurements of optical rotation do not give an adequate description of rotatory properties, though they have often proved useful in the characterization of proteins..." it is obvious that the author has some other work in mind. The first thing the analysis tells us, possibly, is that he has left out the necessary reference to an earlier paper by himself or some one else. Secondly, if the paper does indeed exist, the analysis will point to that paper as a further guide to indexing.
(6) Elaborate transformations may not be necessary for an indexing operation such as Chemical Abstracts. What may be needed is an indexing grammar or syntax that will rearrange sentences to a "canonical form" (standardized). Even this may not be necessary if the analysis can reveal the important main headings and sub-headings needed. Then, instead of a "modification" which is a portion of a transform we might just use the original sentence. This is the kind of thing Luhn has in mind in his statistical approach to finding the most useful sentences of a text [see 5].
(7) An illustration of the difficulties we face is indicated as follows: in paragraph 3 of the Linderstrom-Lang paper, a key word is POLYPEPTIDE SYSTEMS. DRUDE EQUATION is another key word. Our problem is finding a mechanism for determining that it is a desirable key-word in this particular document (as well as in our index dictionary) and then finding the mechanism for constructing a useful indexing "sentence" or phrase such as "POLYPEPTIDE SYSTEMS obey one term Drude equation". Such selectivity may be more difficult to work out than the discourse analysis itself.
(8) The solution may be found by analyzing the "thinking" processes of indexing. Why, after reading a certain percentage of a text, do I decide that an entry is desired? For example, starting with the simplest part of the jobthe titlewhy do I index "Insulin" and "Sangers A-chain" and not "the structure of" and "as compared to that of". There is a logical justification for using "structure" as a key word but the practicalities of indexing prevent this since there are thousands of articles on "structure". Whether we use "structure" as a heading or not, it is interesting (if not obvious) to observe that nouns are selected for indexing, whereas, articles, verbs, etc., are not. (When a verb appears to be indexed, it is really a transform of a noune.g. "How to repair metal pipes that corrode" is transformable to "How to repair corrosive metal pipes". Such verbs usually occur so frequently they do not warrant indexing.)
(9) Indexing may involve transformations of the following type: The Structure of Insulin as Compared to that of Sangers A-Chain. (Title)
![]()
VERBALIZATION
The structure of Insulin is compared to the structure of Sangers A-Chain.
![]()
Insulin, the structure of, is compared to structure of Sangers A-Chain.
![]()
Sangers A-Chain, structure compared to that of Insulin
![]()
(10) In Note #3, attention was drawn to the phrase "one phase". Though this is an important piece of information, it is not the problem investigated, which is "The Structure of Insulin". As said before "One phase of this research" is considered metadiscourse. The phrase or period following it would be indexed. Here are the transformation patterns:

"The dependence" is a noun but we can assume that in a dictionary operation preceding any analysis this term would not occur since the resulting index would be overloaded with entries under it. It is an "operating" term. Actually it is a nominalization of the verb "depend" and might therefore be automatically eliminated. Nouns may prove to be the only items required for indexing. (To what extent are verbs used in indexing, if at alland of the nouns that are used, which are really derived from verbs?)
(11) Using the phrase "it was found" in paragraph 3 as an indicator, the indexer obtains the following index entries:

In all of the above it is assumed that Ss have been delineated. It is no small problem we face in having the machine decide that the remainder of this sentence should not be indexed. However, the semi-colon gives us one clue; does the remainder of the sentence contain any "indicators"? The machine, however, would use the same guides given the indexera term like "specific rotation" may not be indexed because it is a generic term, as is wavelength, and neither are linked to other nouns in these sentences. In other words, an important criteria in indexability is the actual occurrence in a text of particular noun combinations and permutations.
(12) For the sake of pursuing the use of metadiscourse statements further we will state that (it is dubious without more experience) the first sentence of paragraph 4 was not indexed because the phrase "in general" occurred. This phrase implies that the sentence is a restatement of known information. In another paper or book it might be just the grammatical indicator we want to include, in the sentence. Its applicability or not must be determined in relation to the importance of the headings used. The second sentence in paragraph 4 is dubious from the point of view of efficient indexing. There have been many articles on the denaturation of protein by urea. It is conceivable that someone interested in that topic would want to find this article. However, the best method of keying it for searching would be to provide a reference to such an article. Nevertheless, the indicator, "in particular" provides a clue that the following index entries may be desired:
Urea, denaturation of protein by
Guanidine, denaturation of protein by
Denaturation of proteins by urea and guanidine
(13) The "specific wavelength determined" might be the most interesting piece of information in this paper and it would not be indexed by any of the conventional systems. Here is another area where DA may be usefulin pointing up new data not easily pinpointed in an indexing operation where timing is important.
The following articles were indexed according to two different systems
to illustrate the difficulties ahead using Discourse Analysis, as well
as other methods, for mechanical indexing.
Article #1
Central Activity of Derivatives of Imidazole Dicarbonic Acid
Yu.S. Borodkin
Farmakol. toksikol. 22(1): 1115 (JanFeb. 1959)
Condensed translation from the Russian by F. Krasovec
Index entries according to Current List systemAbstract. Study of dimethylamide-1-methylimidazole-di-carbonic acid (IEM-168) and dimethylamide-imidazole-dicarbonic acid (IEM-163) on conditioned reflex and pentobarbital hypnosis in mice. IEM-168, 2030 mg/kg s.c., decreased conditioned reflex; in doses of 3080 mg/kg s.c., it potentiated pentobarbital hypnosis. TEM 163, 530 mg/kg s.c., increased latent period of conditioned reflex without any effect on motor reaction; doses of 30 mg/kg ks.c. potentiated pentobarbital hypnosis. It should be noted that IEM-168 is chemically related to caffeine, and IEM-163 to theophylline.
(1) REFLEX CONDITIONED
inhib. by & increased by imidazole-dicarbonic acid derived in mice.
(2) DRUG POTENTIATlON
pentobarbital by imidazole-dicarbonic acid deny.
(3) PENTOBARBITAL
potentiation by imidazole dicarbonic acid derived
(4) CT IMIDAZOLE AND IMIDAZOLINES
imidazole-dicarbonic acid derived, eff. on conditioned reflex and pentobarbital
hypnosis in mice.
Index entries according to pharmacologists indexing system
(1) Reference drug on function
(2) Small animal
(3) Drug activity comparison
(4) Multiple action
(5) Central Nervous activity
(6) Behavior-conditioning
(7) Motor activity
(8) Reference drug on action of other drug
(9) Consciousness
In the following article, it is important that this drug is affecting acetylcholine
metabolism and therefore the response of muscle to nervous control. This
relationship must be distinguished by the indexer. We dont want
to indicate that this is an article on "the effect of acetyicholine on
respiratory function in certain disease states", which in fact it is, but
it is of minor importance to the pharmacologist.
Article #2
The effect of Drugs in Acetylcholine-induced
Bronohial Obstruction
D.E. Frank
Annals Allergy 17(2): 200208 (Mar.Apr. 1959)
Current List type indexingAbstract. Acetycholine in aerosolized form markedly diminished vital capacity and maximum breathing capacity in 18 chronic asthmatic subjects. Diphemanil methylsulfate s.c. (Prantal), eminophylline iv., epinephrine s.c. and hydroxypropyl theophylline iv. (in order of effectiveness) improved ventilation function. As pretreatment, only Prantal and epinephrine were effective. Prantal and epinephrine acted synergistically. Because severe attacks could not be reversed by an anticholinergic drug alone, intercellular retention of acetylcholine at bronchial muscle level may continue to act until counterbalanced by adrenergic action.
(1) ASTHMA
etiol., acetylcholine as factor; eff. of diphemanil, amino-phylline and epinephrine
(2) ACETYLCHOLINE
in etiol. of asthma
(3) PARASYMPATHOLYTIC
diphemanil methylsulfate, eff. on vital capacity in asthma.
(4) RESPIRATION
increased by diphemanil, aminophylline and epinephrine in asthma.
(5) THEOPHYLLINE
vital capacity in asthma increased by
(6) DRUG POTENTIATION
epinephrine by diphemanil in asthma
(7) EPINEPHRINE
vital capacity in asthma incr. by; potent. by diphemanil
More specific indexing of same article by pharmacologist
(1) ref. drug on action on other drug
(2) ref. drug on action of disease state
(3) drug comparison
(4) pre-treatment
(5) asthma
(6) respiratory reserve
(7) reference drug on metabolism
(8) muscular control
(9) neuromuscular transmission
(10) parasympathetic neuroeffector
Article #3
Perphenazine in Urology and Surgery
L. Stewart
Am. Practitioner 10(5): 845848 (May 1959)
Current List indexingAbstract. Trilafon, 5 mg im. or i.v. followed by oral doses of 1664 mg/day, relieved severe emesis associated with urologic disease in 7 patients. Clapping tremor, probably a potentiation of uremic twitching, developed in 2/4 patients with terminal uremia. Operative and postoperative vomiting was relieved by 5 mg i.m. in 37 patients. Prolonged hiccoughing in 2 patients was terminated by Trilafon. Mild vertigo was only side effect reported.
(1) PERPHENAZINE
in urology, ther. of N & V, hiccough, and anxiety and tension
(2) PRE, PER, AND POST OPERATIVE SEDATION
perphenazine in urol. dis.
(3) HICCUP
ther: perphenazine, mention
(4) NAUSEA AND VOMITING
ther: perphenazine in urol. dis.
(5) URINARY DISORDERS
N and V in, ther. with perphenazine
Specific indexing used by pharmacologist
(1) vomiting center
(2) renal disease
(3) uremia
(4) postoperative period
(5) hiccough
(6) nervous control
(7) man
(8) peroral
(9) intramuscular
(10) reference drug on action of disease
From these three examples it will be evident that: (1) Titles of articles are not sufficient even for producing index entries of the Current List type. (2) Even the vocabulary of the abstract did not reveal some of the entries used. For example, SEDATION in the third example. However, this might be considered "implied" by the fact of an operative condition. Nevertheless there are surgical operations that are performed without sedation. (3) Not all the key words of the title or abstract become index entries as e.g. Urology even though UROLOGY is a perfectly good index term. (4) The index entries used are not always transforms of sentences which exist in the text of the abstract. (5) The index entries used are not necessarily transforms of stretches of text, but require a whole series of complex transformation operations which must be investigated further. (6) According to the circumstances certain transformation operations are extremely important and are of the "antonymous" type, i.e. the original text is transformed into an antonymous relationship rather than that which was reported. (7) Significant remarks are not always indexed though they may be desirable in an abstract as e.g. "It should be noted that IEM-168 is chemically related to caffeine, and IEM-163 to theophylline. (8) Serious consideration must be given to the question of whether a transformational relationship exists between a set of a priori criteria, as, e.g. "drug activity comparison" and the manner in which authors report such comparisons. In the Linderstrom-Lang article the term "compared to" was used. In this article it was not.
From Chemical Abstracts, Volume 48: 13, 761h (1954)Biological Chemistry
The Structure of Insulin as Compared to that of Sangers A-Chain
K. Linderstrom-Lang & John A. Schellman
Biochim. Biophysica Acta 15: 156157 (1954)
Indexing of this article as found by checking 1954 Subject Index to Chemical AbstractsThe dependence of the rotatory properties of proteins on wave length was studied. All the systems obeyed equation: ..., where ... is specific rotation, ... is the wave length of the measurement, and A and ... are empirical constants.; A is a function of temp., pH, ionic strength, denaturation, etc. and ... is a function of drastic change in the protein system such as denaturation by urea or guanidine or titration to pH between 10.5 and 12.0. Values of ... for native globular proteins (e.g. insulin b-lactoglobulin, etc.) were grouped higher than those for ixidized A-chain of insulin, clupeine, chloride, or b-lactoglobulin, denatured by urea at pH 10.9. It is suggested that ... may provide a measure of the presence of secondary structure in polypeptides, having values over 2400 Å for the ordered configuaration of native protein and under 2300 Å for polypeptides in disordered states. The oxidized A-chain of insulin, with ... -2300 probably is largely unfolded in aqueous solution.
Proteins, rotatory dispersion of Insulin, structure of, Sangers A-chain and
The article was not indexed under any of the following, all of which were checked.
Sangers; denaturation(x-ref. to proteins); polypeptides(x-ref. to peptides); proteins, optical rotation (even though there was an entry for "opt. rot. of denatured protein, i.e. another article); b-lactoglobulin; optical rotation; Drude equation (no heading for this); urea; guanidine; clupeine;
Thus, we now have a concrete case and can make some comparisons. In Harriss tables the vocabulary which has been stressed is indeed to be found in the CA abstract. This is important as it indicates that Discourse Analysis could be very useful as a guide to the abstractor. However, this same vocabulary is not to be found in the indexing of this abstract. That is why it is so important to be precise about "information retrieval". An abstract is not a retrieval device until and unless it is "indexed," or unless it is searchable. Perrys abstracts are presumably searchable. Harriss tables, presumably are searchable but how this is done remains to be determined.
It is apparent from the indexing done by CA that only the title
and first sentence were indexed. It could be debated whether the remainder
of the abstract should have been indexed. However, CA does have
a practical space problem and we can assume that even the largest memory
computer will have a similar space problem.
References
[1] back
E. Garfield, Mechanical indexing, machine indexes, and the preparation
of indexes by machine methods. Paper presented at the Symposium on Machine
Techniques in Scientific Documentation, 3 March 1953, Johns Hopkins
University, Baltimore, MD.
pdf
available
[2] back E. Garfield, Discussion comments. In: Proceedings of the International Study Conference on Classification for Information Retrieval, 1317 May 1957, Dorking UK (Pergamon, New York, 1957) 91, 98, 106. pdf available
[3] back J.W. Perry, The Western Reserve University searching selector. In: J.W. Perry and A. Kent, eds. Tools for Machine Literature Searching (Interscience, New York, 1958) 489579.
[4] back R.S. Casey, J.W. Perry, MM. Berry and A. Kent, eds. Punched Cards: Their Application to Science and Industry (Reinhold, New York, 1958).
[5] back H.P. Luhn, The automatic creation of literature abstracts, IBM Journal of Research and Development 2 (1958) 159165.
[6] back H.P. Luhn, Keyword-in-context for technical literature (KWIC Index) (ASDD Report RC-127, IBM, Yorktown Heights, NY, August 1959).
[7] back SM. Newman, Linguistics and information retrieval: toward a solution of the Patent Office search problem. Paper presented at the Eighth Annual Round Table Meeting on Linguistics and Language Studies, Institute of Language & Linguistics, School of Foreign Service, Georgetown University, 12 April 1957 (Monograph 10, Georgetown University Press, Washington, DC, 1957).
[8] back SM. Newman, Problems in mechanizing the search in examining patent applications Patent Office Research and Development Reports (US Department of Commerce, Washington, DC, 1956).
[9] back Z.S. Harris, Methods in Structural Linguisitics (University of Chicago Press, Chicago, IL, 1951).
[10] back Z.S. Harris, H. Hiz, AK. Joshi, B. Kaufman, C. Chomsky and L. Gleitman,Transformations and discourse analysis projects (Department of Linguistics, University of Pennsylvania, Philadelphia, 195961).
[11] back R. Busa, Electronic technology in the mechanization of linguistic analysis, Nachrichten für Dokumentation 8 (1957) 2026.
[12] back S.V. Larkey, The Welch Medical Library Indexing Project, Bulletin of the Medical Library Association 41(1953) 3240.
[13] back Z.S. Harris, The transformational model of language structure, Anthropological Linguistics 1 (1959) 2729.
[14] back Z.S. Harris, Linguistic transformation for information retrieval. In: Proceedings of the International Conference on Scientific Information, 1958 (National Academy of Sciences, Washington, DC, 1959, Vol. 2) 937950.
[15] back Z.S. Harris, Co-occurrence and transformation in linguistic structure, Language 33 (1957) 283340.
[16] back CL. Bernier and E.J. Crane, Indexing abstracts, Industrial Engineering Chemistry 40 (1948) 725730.
[17] back ID. Welt and J.T. MacMillan, The world literature on cardiovascular drugs, Bulletin of the Medical Library Association 46 (1958) 6072.
[18 back ]M. Taube, Studies in Coordinate Indexing, 5 volumes (Documentation, Inc., Washington, DC, 19531959).
[19] back E. Garfield, Citation indexes for science, Science 122 (1955) 108111.
[20] back
K. Linderstrom-Land and JA. Schellman, The structure of insulin as compared
to that of Sangers A-chain, Biochim. Biophys. Acta 15 (1954) 156157.