Many different and interesting systems have been devised for the coding
of chemical compounds (see references 1-23).
Chemical codes which do not attempt to describe compounds completely
and uniquely may be termed generic codes. These codes deliberately
sacrifice specificity for convenient grouping of compounds. The various
generic codes differ primarily in the number and kind of groups they
can create, the number of compounds included in each group, and the
manner of retrieving data from the coded material.
Rotadex consists of a rotated index with three aspects: molecular
formulas, generic structural codes, and the addresses where the
references are made to the compounds. Any combination of the structural
code and elemental composition may be used to define or narrow down a
field of search. Each Rotadex structural code contains the same number
of characters. In the examples described below, four-character
structural codes will be used. In Figure 1 we see the chemical
structure of N,N-dibutyl acrylamide together with its molecular
formula, C11 H21 NO, and its Rotadex structural
code 99QT.
|
|| Bu2N-C-CH=CH2 |
|
| C11H21NO |
99QT
|
|
|
|
Each character of the structural code is obtained from a separate
table. The assignment of chemical features to these tables is tentative
and the following should be considered only as examples. The first
character of the code 99QT comes from Table 1. The presence or absence
of any of five chemical features may be designated by one of the 32
alphanumeric characters given in the righthand column. Note that the
letters in the body of the table are merely mnemonic abbreviations for
the chemical features. In the table, r represents any homocyclic ring
(e.g., cyclopentane), 2r any homocyclic two-ring fusion (e. g.,
naphthalene), any homocyclic three-ring fusion (e.g., anthracene), 4r
any homocyclic four- (or greater) ring fusion (e.g., steroids), and any
spiro configuration. It is thus seen that a benzene-substituted
naphthalene would be described by the letter P taken from this table.
Note that 2r does not indicate two separate benzene-like rings, but
rather one or more two-ring fusions.
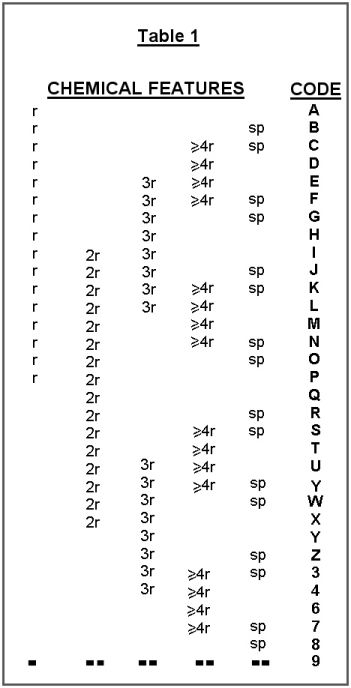
The digit 9 is used here (and in the remaining tables) to signify the
absence of all five of the chemical features covered by a character of
the structural code. The first 9 in the code for N,N-dibutyl acrylamide
describes, therefore, the absence of any homocyclic ring structure or
spiro configuration.
In Table 2 we see an analogous table from which the second character of
the structural code is derived. The second 9 in the code 99QT indicates
the absence of any heterocyclic ring structure or bridge configuration
in the compound.

Table 3 is used for the third character of the structural code which describes five chemical configurations of oxygen or sulfur (with no differentiation between them). This character indicates the presence of any acid group (ac whether free, salt, or ester), carbonyl group (one), hydroxyl group (ol) , bond-O-bond (ox), and the presence of two oxygens or sulfurs attached through double bonds to the same element (diox). The Q in the code 9QT thus shows that, of these chemicals, only one is present.

The fourth character in the structural code, Table 4, describes nitrogen or phosphorus as being present in tertiary form, az, with at least one hydrogen attached, am in the N-N or PP configuration, diaz, or in a quaternary state, ±. The chemical feature diaz is aleo used to indicate any contiguous repeated hetero-elements. Examples of this include: S-S, O-O, B-B, etc. The fourth character is also used to show the presence of any non-resonating unsaturations, ene. These unsaturations are named in any case where they are not explicitly included in another chemical feature, that is to say, ac, one, diox, do not cali for renaming the but all other instances do. The T in the code for N,N-dibutyl acrylamide therefore indicates a tertiary nitrogen a double or triple bond, az, ene.
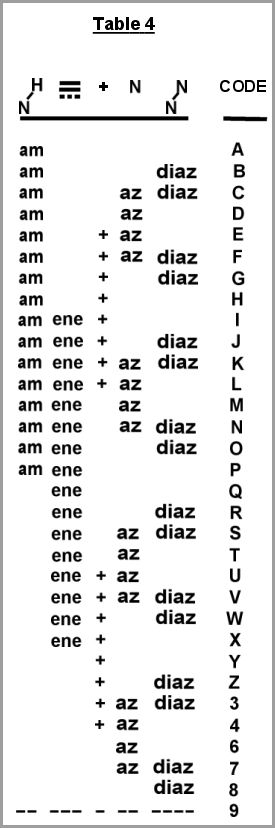
The addition of a fifth character to the Rotadex structural codes might
be useful if it were desirable to indicate additional chemical features
such as the presence of metallic salts, organic salts, polymers,
incompletely-known structures, etc. With four characters, one may write
324 or over a million different structural codes. Though
almost everyone of these codes is theoretically acceptable, they will
not, of course, find equal use in actual applications. Further, it is
from a study of these frequencies that will come improved assignment of
chemical features to the tables.
The Rotadex structural codes were designed to facilitate the
unambiguous assignment of compounds to proper categories. There is
little double-naming of substructures. When a spiro configuration is
preserit the individual moieties are named independently in addition to
the spiro designation. For example, spiropentane (cf. Table 1) would be
indicated by the letter B in the first position of the structural code,
specifying the presence of the homocyclic rings, r, as well as the
spiro configuration, sp. Similarly, Table 2, the component rings of a
bridge (after eliminating the bridge) are coded in addition to the
bridge, br, itself. In order to make the naming of the component rings
of a bridge unambiguous, a hierarchy must be established for the
elimination of “arms” from the structure. Homo-element arms (carbon)
are eliminated first, always starting from the shortest and moving
toward the longest arms. Thereafter hetero-element arms are eliminated,
again starting from the shortest arm. This elimination procedure stops
as soon as the remaining structure can no longer be termed a bridge
compound. At this point the remaining ring configurations are coded.
The bridge is designated whether the compound is homo- or heterocyclic.
Larger chemical features are coded rather than their component parts.
For example, acid groups are not also coded for the one or ol groups.
Acid groups and diox configurations are considered the largest
of such features since they involve at least three groups of atoms.
In the case of ties, priority is assigned to chemical features in the
order in which they appear in the coding tables. Thus, the sulfo
radical is coded as ac, one rather than diox, oh.
The ox feature, Table 3, includes ethers and epoxy compounds. The epoxy
structure is double-coded for a heterocyclic single ring, h, as well as
for the ox. Epoxy structures constitute the only case where
hetero-elements contained completely within a ring are
double-indicated. Otherwise hetero-element substructures are indicated
only when all or part of the substructure lies outside the ring. For
example, large cyclic ethers are named only as a heterocyclic ring, but
cyclic ketones have the one indicated since this extends outside the
ring. Similarly, the am in piperidine is indicated (since the hydrogen
extends outside the ring) and so for diaz when one of these
nitrogens is outside the ring.
Hydrazine derivatives are always coded as diaz and, whenever
one or more hydrogens remain unsubstituted, the derivatives are
double-coded am also.
Since the quaternary charge implies the presence elsewhere in the
compound of a negative charge, all quaternaries, phosphoniums,
sulfoniums, etc., are indicated whether appearing in a ring or not.
It should be noted that because of the ancillary use of the molecular
formula, the Rotadex structural code may conveniently group together
chemical features which are coded differently by other codes.
Rotadex does not distinguish between substitutions located on rings or
located on chains, nor does it signify the exact number of times a
chemical feature appears in a compound.
Preliminary tests suggest that a four-character structural code may be
assigned to the average compound in lees than half a minute. This
attribute and the terseness of the code make it particularly suitable
for incorporation in large-scale coding and printing operations.
Generic searching with Rotadex is facilitated by
a fixed-column format.24 This assures
the user that a scan of a specific column will disclose all references
to a given feature, whether it be part of the elemental composition or
the structural code.
“Rotation” of molecular formulas25 and chemical codes are performed without
actually moving the characters out of their fixed-column positions.
Rather, the formulas are sorted successively on each element and the
codes on each character. Whichever position constitutes the primary
sort key, the elements or characters to the right constitute
successive, minor sort keys. Minor sort keys to the right of the last
character continue with the first character (in a wrap-around fashion).
A primary sort on hydrogen is omitted (Figure 2). The order of the
elements in the fixed columns reserved for molecular formulas is: C, H,
N, O, P, S; X (all halogens); and M (all remaining miscellaneous
elements.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Within the X and M columns, the various elements are alphabetized.
Since common elements appear in fixed columns (C through S), only the
number of atoms of each of these elements need be listed, and letters
may be replaced by headers of the atomic symbols over the columns.
Allowances are made for the maximal, usual number of digits required
for these elements. Thus, two column positions are reserved to indicate
the number of carbons, two for the number of hydrogens, and two for
oxygen. One column each is reserved far the elements nitrogen,
phosphorus, and sulfur. The halogen and miscellaneous fields each
include three columns since they must also contain up to two
alphabetical characters indicating the elements. In any case, when the
actual number of digits exceeds the allotted columns, the excess lower
order digits are dropped to the next lower line where they and a
lozenge are printed in an otherwise blank line.
The printout of this molecular formula aspect of the index reveals
which column is the primary sort key by the obvious grouping in that
area. For instance, when the sort key has moved to nitrogen, there
appears a listing of all the molecular formulas headed by a block of
blanks in the nitrogen column followed by a continuous string of 1's
followed by a continuous string of 2's, etc. Figure 2 illustrates what
a fragment of the actual index may look like and is taken from a
hypothetical section where nitrogen is the primary sort key.
Searches are best performed with Rotadex by first defining the minimal,
elemental requirements and parameters of acceptable structural codes.
In some searches, the presence of a relatively rare element provides a
convenient starting point. Any search involving boron, for instance,
would probably best begin at the portion of the index where the data
has been sorted first on the miscellaneous elements. There, under the
B's the user will find all compounds containing boron and within this
group the compounds will be arranged by the number of borons present.
From this point, the user may scan other elemental requirements and
verify an acceptable structural code before looking up specific
compounds at their addresses.
Many searches will allow the user to subdivide the total file by
scanning elements successively from left to right. Final selection of
appropriate compounds can again be made by the acceptable structural
codes.
Whenever cumulative molecular formula indexes are compiled, some
molecular formulas will accrue unwieldy numbers of compound addresses.
These clusters are discouraging to the user since many or most of the
compounds in a cluster differ from the type of compound desired. The
inclusion of the Rotadex structural code with the address of each
compound allows for further subdivision of these clusters in accordance
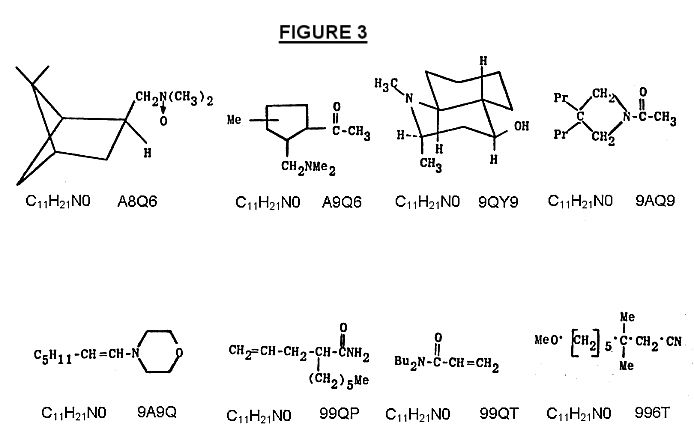
with the chemical features required by the search. Figure 3 shows a
sampling of the compounds from the 36 addresses clustered under the
common molecular formula C11 H21 NO, as it
appeared in a biennial cumulative index of Index Chemicus. When Rotadex
structural codes are assigned to these compounds, two cases of
identical codes are encountered. In the first instance, a series of
stereoisomers of decahydroquinolines all receive the same structural
code 9QY9, and turn out to be separate references to the identical
compound N,N-dibutyl acrylamide. The remaining compounds receive
differing structural codes.
Another method of searching Rotadex calls for first entering the
portion of the index where compounds have been sorted primarily on the
structural codes. Table 5 is a summary of the four preceding tables,
and it is used to decide which codes will be compatible with a given
search. We see that any given chemical feature may have been coded (in
the appropriate column) by any of 16 characters, depending upon what
other chemical features are also found within the compound.
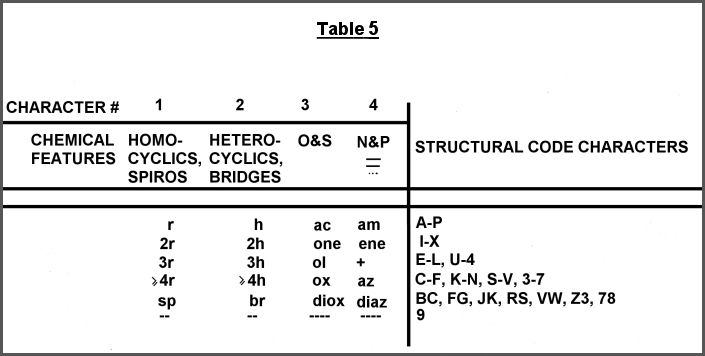
If a generic search were to be conducted for all N-N disubstituted
acrylamides, the minimal elemental requirements of C3 H3
NO would be of little help. The structural code, however, would narrow
the search considerably. No restrictions would be imposed on the first
or second characters of the structural code in this case, but the third
character must be one of the letters of the alphabet I-X since there
must be at least one =O present in any acrylamide. Note that the O in
the code 99QT meets this requirement. Furthermore, the fourth character
must indicate a double bond a tertiary nitrogen. The only characters
which meet the requirement for a double bond (I-X) together with
tertiary nitrogen (C-F, K-N, S-V 3-7) are K-N, S-V. Note that the T of
the code 99QT meets this requirement.
The generic search for N-N disubstituted acrylamides might, therefore,
be performed by first entering the index at the section where compounds
have been sorted on the fourth character of the structural code. All
entries in the two alphabetical portions, K-N and S-V, would then be
scanned for a character in the third position equal to I-X. All N-N
disubstituted acrylamides would be included in these results. The
amount of “noise” or extraneous compounds also included, will vary with
individual searches.
In summary, Rotadex is a new proposal for indexing and listing chemical
compounds. The data is sorted repeatedly on each part of the molecular
formulas and structural codes. When printed in fixed-column format,
this enables the user to narrow the range of his search rapidly
according to many combinations of restricting parameters.
The structural codes devised for Rotadex are terse and simple. The
chemical features described by the structural code may be combined as
desired to form relatively broad descriptors of the chemical
structures. Clusters appearing under identical molecular formulas are
subdivided by the structural codes.
Structural codes may be entered directly to perform generic searches.
Though designed to facilitate hand searches of printed indexes, Rotadex
is also well suited to mechanical and computer searches.
Coding and searching of compounds is independent of systems of
nomenclature and can be performed very rapidly. Only a few minor
hierarchical rules. are required. Chemical features to be coded are
mutually exclusive. Substructures may be described by the fragmentary
chemical features which they contain.
It should also be possible to write a computer
program that will automatically convert systematic chemical names of
compounds into corresponding molecular formulas and structural codes by
an extension of Dr. Garfield's26
alogrithm for translating chemical nomenclature.
BIBLIOGRAPHY
- back to text Anonyrnous, “A Method of Coding Chemicals for Correlations and Classification,” National Research Council, Washington, D.C., December 12 (1949)
- Bonnett, H.T. and D.W. Calhoun, “Application of a Line Forimula in an Index of Chemical Structures,” J Chem Doc, 2, 2 (1962)
- Cahn, A., “A Simple, Nonmechanical Coding System for Information Retrieval in Organic Chemistry,” Research and Development Division, Lever Brothers Co., Edgewater, N.J.
- Crane, E.M. and M.M. Berry, “The Composite Volunteer Notation System for Molecular Structure Formulas,” Chem Eng News, 33, 2842 (1955)
- Dale, E. and K. Heumann, “Statistical Information on Component Parts of Chemical Cornpóunds,” Chemical Biological Coordination Center, National Academy of Sciences-National Research Council, March (1955)
- Duffin, W.M., J Chem Doc, November (1961)
- Dyson, G.M. and E.F. Riley, “Use of Machine Methods at Chemical Abstracts Service,” J Chem Doc, 2, 19 (1962)
- Feidman, A., D.B. Holland, and D.P. Jacobue, “The Automatic Encoding of Chemical Structures,” l4lst Meeting ACS, Washington, D.C., March (1962)
- Frome, J. and J. Leibowitz, “A Manual for Coding Steroids,” Patent Office Research and Development Report No. 11, Novernber 17 (1958)
- Frome, J., et al, “Manual for a Punched Card Retrieval System for Organic Phosphorus Compounds,” Patent Office Research and Development Report No. 22, November 24 (1961)
- Frome, J. and P.T. O'Day, “PACIR: Practica 1 Approach to Chemical Information Retrieval,” J Chem Doc, 2, 248 (1962)
- Frome, 3., et al, “ASTIA Chemical Thesaurus,” Armed Services Technical Information Agency, Arlington, Va., December (1962)
- Gelberg, A., W. Nelson, G.S. Yee, and E.A. Metcalf, “A Program for Retrieval of Organic Structure Information,” J Chem Doc, 2, 7 (1962)
- Gordon, M., et al., “Chemical Ciphering; a Universal Code as an Aid to Chemical Systernatics,” Royal Institute of Chemistry, Great Britain (1948)
- Hayward, H.W., “A New Sequential Enumeration and Line Formula Notation System for Organic Compounds,” Patent Office Research and Development Report No. 21 (1961)
- Norton, T. R., “A Manual for Coding Organic Compounds,” (unpublished paper) May 27 (1953)
- O'Connor, 3., “A Note on the Possibility of a Divided Structure File Permitting Arbitrary Substructure Searchee,” University of Pennsylvania, Philadelphia, Pa.
- “Rules for IUPAC Notati on for Org anic Compounde,” John Wiley & Sons, Inc., N.Y. (1961)
- Silk, 3., “A Linear Notation for Organic Compounds,” Imperial Chemical Industries, Ltd., Jealott's Hill Research Station, Bracknell, Berkshire, England (privately published) May (1961)
- Smith, E.G., “Machine Searching for Chemical Structures,” Science, 131, January 15 (1960)
- Verkade, P.E., “The IUPAC Ciphering System for Organic Compounds,” Chemisch Weekblad, 58, 137-143 (1962)
- Wheller, K.W., et al, “A Structure Code for Organic Cornpounds,” Am Doc, 9, 198-207, July (1958)
- Wiswesser, W. J., “A Line-Formula Chemical Notation,” Thomas Y. Crowell Co., N.Y. (1954)
- back to text O'Connor, 3., “The Scan Column Index,” American Documentation, April (1962)
- back to text Garfield, E., “Generic Searching by Use of Rotated Formula Indexes,” l4lst Meeting ACS, Washington, D.C., March (1962)
- back to text Garfield, E., “An Álgorithrn for Translating Chemical Names to Molecular Formulas,” l4lst Meeting ACS, Washington, D.C., March (1962) PDF FILE